天玑9400详解:AI时代,旗舰芯拿什么引领?
联发科将最近刚刚发布的天玑9400称为旗舰5G“智能体AI芯片”——所谓的“智能体”究竟是什么意思?对手机又有什么价值?本文详细剖析了天玑9400的关键技术,来尝试一探究竟...
在生成式AI技术进入手机之后,手机开始具备理解自然语言,并做出智能回应的能力。好比我们和手机说“我饿了”,手机已经能够理解该意图,并主动打开点餐app。rbvesmc
但这在联发科看来仍然是不够的。最近的天玑9400发布会上,联发科技资深副总经理徐敬全说,“前沿AI技术将进入新的转折点”,令智能手机转向“智慧手机”。rbvesmc
比如在上述“我饿了”的场景中,手机不应该只是帮忙打开个点餐app就结束,而应当知道用户的个性化需求,且可自主感知环境,基于上下文自动化点餐操作...rbvesmc
 rbvesmc
rbvesmc
徐敬全在发布会现场演示与手机AI助手交互,能够自动在肯德基app中,基于当前的早餐时间,个人喜好,及当下需求进行食物的推荐及下单;且与徐敬全进行多轮交流和对话。这个看似简单、符合直觉的操作,实则涉及到底层芯片算力供给、上层生态搭建等全套基础设施问题。rbvesmc
虽然天玑9400手机芯片的技术要点并不单纯在AI上,不过借着天玑9400的发布,我们有机会更深入地理解所谓的“智慧手机”中的“智能体AI芯片”,究竟需要做成什么样;以及在推进Android智能手机发展过程中,联发科又做了哪些事。rbvesmc
文章篇幅较长,可按照索引做选择性阅读:rbvesmc
Part 1,天玑9400概览;rbvesmc
Part 2 & Part 3,CPU与天玑调度引擎;rbvesmc
Part 4,NPU与智能体化AIrbvesmc
Part 5,GPU与图形/游戏rbvesmc
Part 6,总结rbvesmc
Part 1:览,3个关键点天玑9400概
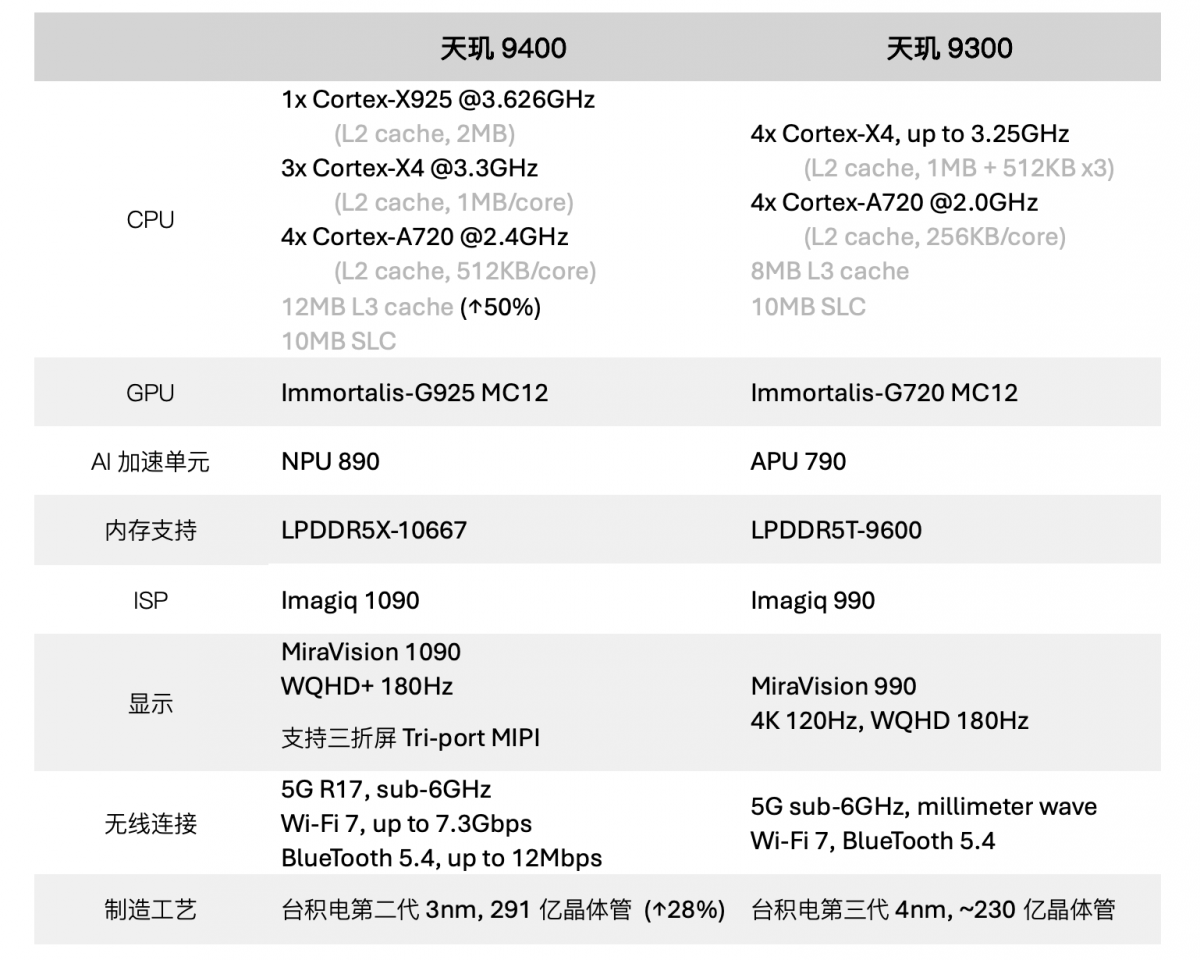
一颗出色的AI手机芯片,首先必须是一颗出色的手机芯片。照例先给出天玑9400的配置一览,顺带对比上一代天玑9300:rbvesmc
 rbvesmc
rbvesmc
基础配置仍有不少亮点是值得谈的。以台积电第二代3nm工艺为基础,CPU、GPU、NPU这三大亮点,后文会做详述。从系统性能角度来看,联发科公布的实验室环境安兔兔v10跑分超过了300万分。rbvesmc
除此之外值得一提的是,天玑的常规强项AI-ISP,可基于DiT模型做摄像头长焦清晰度强化;也能覆盖全焦段做HDR;支持8K杜比视界;藉由新的缓存架构,进行4K60fps视频拍摄时,整机功耗比前代降低了14%;新版显示引擎着眼于”三通道显示“,对三折叠屏手机做出了更高分辨率和刷新率的支持(5K @144Hz)…rbvesmc
无线连接部分的提升也是天玑9400的更新重点。前不久的媒体会上,联发科提到发布一颗4nm短距连接Wi-Fi/蓝牙芯片,配套天玑9400平台,就能实现三频并发Wi-Fi 7总共7.3Gbps吞吐——与联发科Filogic路由器芯片搭配,连线距离增加30米;以及蓝牙12Mbps带宽,蓝牙终于也能拿捏384KHz采样率音频;rbvesmc
基于BLR(Bluetooth Long Range)125Kbps技术,实现“公里级”(1500m)蓝牙连接——这项技术的实践在OEM厂商侧主要体现在这几天讨论度颇高的公里级“无网蓝牙通信”...至于通信功耗的进一步降低等个中细节,实际都可拿来详谈...rbvesmc
 rbvesmc
rbvesmc
无奈篇幅有限,这些都不会作为本文重点去谈。实际上,联发科自己对于天玑9400的关键信息总结,概括的“强”“慧”“猛”三大特性,分别谈的是“强”——CPU的“PC级架构”,“慧”——智能体化AI,“猛”——体现在3A游戏上。对应到处理器硬件,也就是CPU, NPU和GPU。rbvesmc
那么我们也从这三个“特性”或角度,来细谈天玑9400的核心技术,以及迈入智能体化AI手机时代的芯片设计。rbvesmc
Part 2:CPU依旧,且“满血”全大核
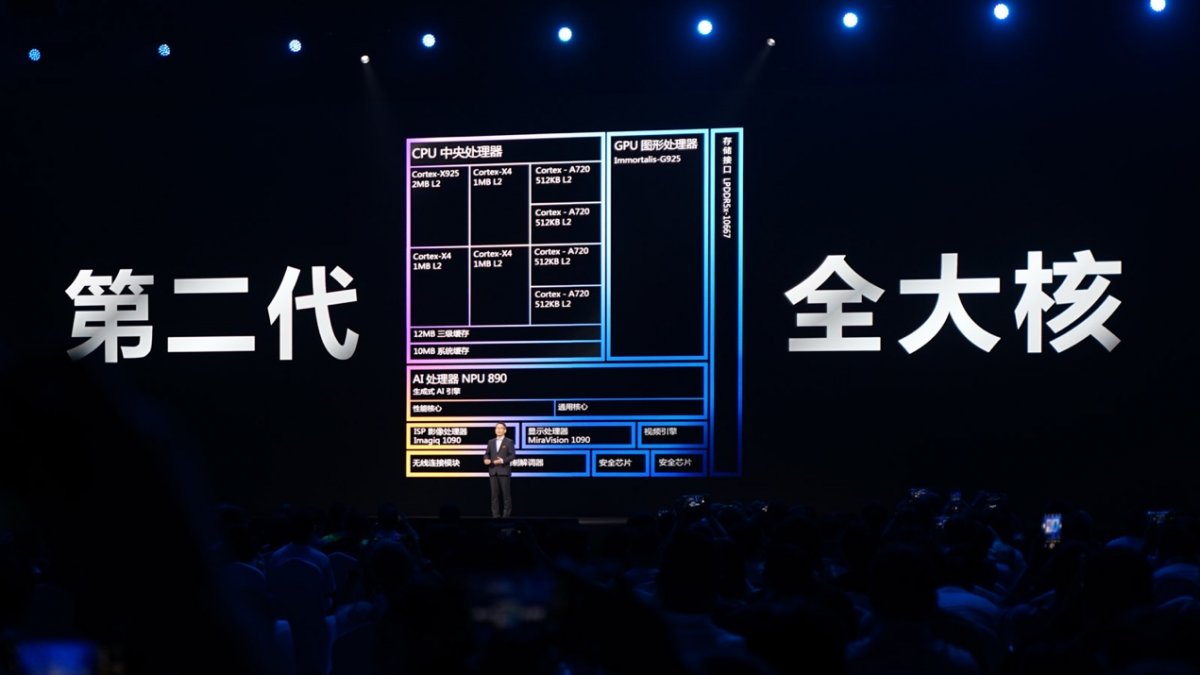
天玑9400的CPU“第二代全大核”是更加名副其实的:除了将其中一颗大核更换为Cortex-X925、进一步提升了频率,更重要的是面向核心个体的L2 cache实现了真正的“满血”。天玑9300可能是受制于4nm工艺的间距与功耗,而未能将CPU的“大核”cache技能点点满。rbvesmc
天玑9400弥补了这一缺失,CPU核心L2 cache总量相比天玑9300增加了1倍;CPU核心共享的L3 cache也扩容50%;SLC(System Level Cache)的尺寸虽然没变,但联发科将其称为SLC 2.0,面向开发者“开放了更多接口”。理论上,CPU及系统性能应当会从存储系统的变化中收益颇多。rbvesmc
配套的内存规格支持,也达成了25%的提升,令天玑9400成为首个支持最高速率10.7Gbps LPDDR5X内存的手机AP SoC。这些算得上是一整套组合拳。rbvesmc
 rbvesmc
rbvesmc
核心之中换新的Cortex-X925是格外值得一提的。联发科在媒体会上指出Cortex-X925是Arm推出的近5代超大核中,性能增长幅度最大的一代,IPC增幅15%;甚至从核心微架构的前端到后端用料,联发科都将Cortex-X925与竞品的大核做了规模比较,可见对性能是相当自信的。rbvesmc
Arm今年中发布了新版CSS平台的多个CPU IP,基于Armv9.2架构。其中最大规模的CPU设计就是Cortex-X925。联发科把天玑9400的CPU称作“PC级”架构,部分依据也来自Arm宣称Cortex-X925的IPC超过了桌面端的Intel和AMD,且该IP本身也面向笔记本应用。rbvesmc
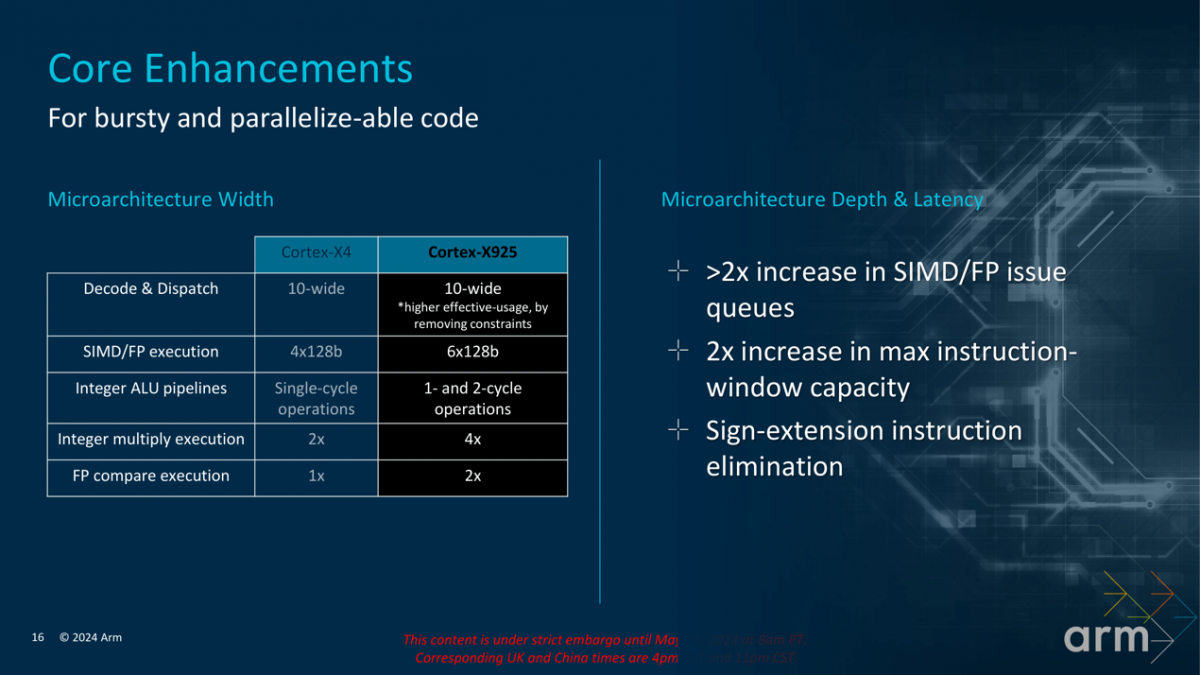
Cortex-X925前端同为10-wide的decode与dispatch宽度,不过对应的指令窗口大小(instruction window)翻了一倍;配套L1-I和TLB都做了扩容。后端执行也大幅加料,如SIMD/FP执行宽度加到6x 128b。外加核心寄存器堆结构提升,ROB容量和指令发射队列扩大等...都表现出这代核心架构的拓宽。rbvesmc
 rbvesmc
rbvesmc
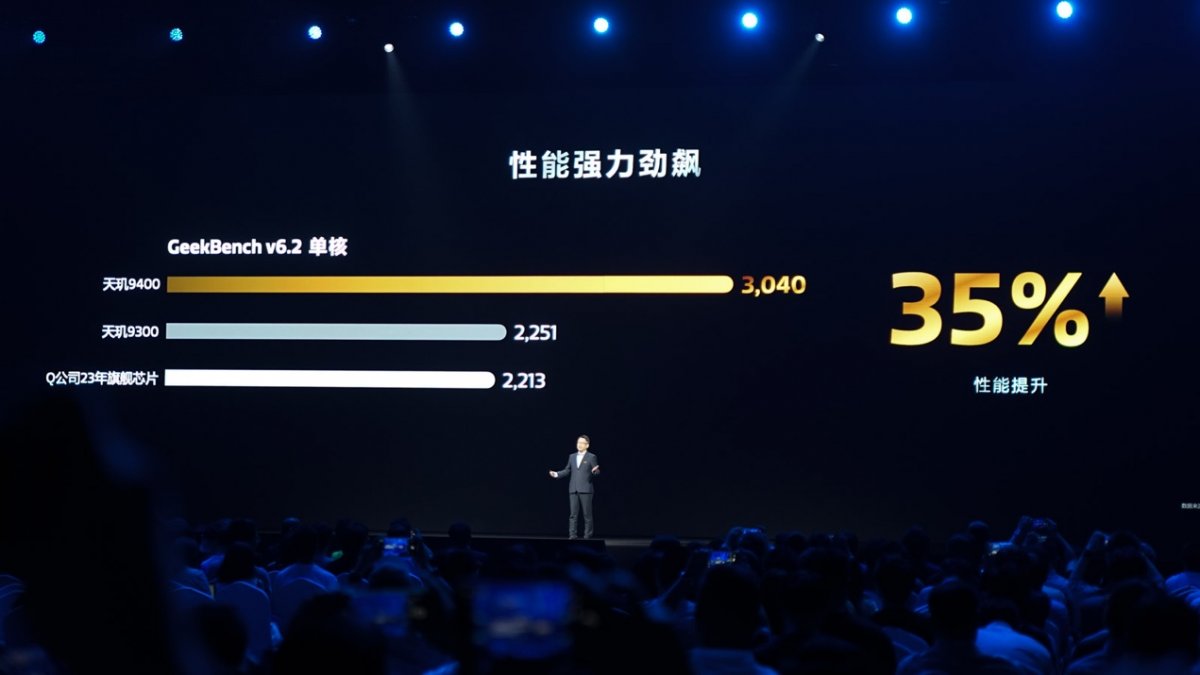
同时DVFS及更多高级电源管理特性,也让X925一定程度兼顾了效率。基于此,联发科在发布会上指出天玑9400的CPU单核性能提升35%(基于Geekbench v6.2)——恰巧和Arm官方给出Cortex-X925约36%的提升幅度相当。rbvesmc
 rbvesmc
rbvesmc
不过需要注意的是,一方面,联发科并没有给天玑9400的Cortex-X925上Arm推荐的最高3.8GHz频率。联发科对此的解释是,由于X925的IPC足够出色,所以并不需要过多推高频率就能达成出色性能,功耗也不会太高。我们认为,此处35%的单核性能提升,有极大部分是由于cache容量的增加;毕竟前代的cache堆料是略有不足的。rbvesmc
性能提升的目标也就达成了。35%的单核性能提升,就当代CPU换代而言实在是个不低的数字——甚至还可能威胁到了素有单核性能之王之称的苹果;也高过高通去年的旗舰(应当是指骁龙8 Gen 3;且不知道高通现在有没有一点后悔收购Nuvia)。rbvesmc
另一方面,联发科也没有按照CSS平台的推荐去搭配大中小核。当然“全大核”本身是现在天玑旗舰芯片的策略,但在第三个核心集群上,联发科也并未选择今年更新的Cortex-A725。联发科的说法是其首要考虑的是达成对应的性能和功耗目标,而非强调一定要用新IP;天玑9400的这种CPU核心组成方式,是谨慎评估后的结果。rbvesmc
谈一下我们的看法:Cortex-A725相较于A720的主要变化,包括有拓宽指令发射序列、ROB大小、更大的L2 cache等。其整体思路也在于将核心规模做大。这样的核心放在Arm推荐的大中小核心搭配方式下,做迭代是成立的。但在“全大核”思路上,当做PPA取舍时,用A725取代A720可能就没那么合理了——尤其在“A”局限的前提下,还要考虑其他大核的资源配给问题。rbvesmc
而且Cortex-A720改用3nm制造,搭配联发科可能做的进一步优化,也能达成效率提升。rbvesmc
 rbvesmc
rbvesmc
不出意外的Geekbench v6.2多核性能测试中,天玑9400的性能相较上代提升28%。全大核思路则令其大幅甩开了骁龙竞品。更关键的是,天玑9400的CPU在达成9300的峰值性能时,功耗降低了40%。rbvesmc
常见app的日常使用场景下,包括看直播、听音乐、微信通话、Wi-Fi下载时的功耗,有着13%-32%的下降。这应当也能体现出即便沿用此前的IP,在新工艺及设计优化下,可获得的能效红利依旧不俗。rbvesmc
Part 3:Android卡顿“玄学”,快要解决了
有关CPU微架构和性能,联发科在媒体会上特别强调了Arm v9的SVE2扩展指令,以及在该指令加速的生态方面,与快手、虹软之间的合作,促成app某些功能的性能强化与功耗降低;并表示SVE2在常规应用里也正走向落地…rbvesmc
受限于篇幅,本文不再就CPU微架构及性能、能效做更多阐述。但从联发科公布的数字不难发现,天玑9400是CPU性能提升相当给力的一代——不曾想天玑9300放完“全大核”的大招,天玑9400还能再做一次强有力的持续追击。rbvesmc
不过性能及能效的直观提升不是全部。CPU部分最后值得一提的,是联发科在媒体会上少见地将较多篇幅放在了软件上:此处的软件特指“天玑调度引擎”。这可能也表现了EDA企业这两年强调的一大趋势:芯片设计越来越无法脱离系统设计存在,以及应用导向的芯片设计。直接表现就是芯片设计企业正“涉足得越来越广”。rbvesmc
 rbvesmc
rbvesmc
更精准的调度策略是达成更佳用户体验的关键,所以这是个更关乎“体验”的技术或特性。联发科总结“天玑调度引擎“的三大特点(1)前台应用,算力倾斜;(2)关键资源,专道专行;(3)据实感知,灵活调整。rbvesmc
这三点似乎都是线程调度上,相当符合直觉的思路。但真的执行起来,可就面临不少问题了。要不然直接用Android默认调度策略就成了。rbvesmc
比如说系统经常“框不准”前台应用的所有线程,故而也很难给予这些线程大幅度的“算力倾斜”。联发科表示,天玑调度引擎有把握完美标注台前线程——在此前提下,将大部分硬件资源给到前台。而且这不是单纯的人工白名单机制,具备了通用性。rbvesmc
另外,天玑调度引擎能够确保系统为台前线程保留资源,避免抢占;以及针对特定场景,可判断动态加入的线程,以分配算力——比如调度引擎知道微信小程序是来源于微信这个母程序,则可给予台前算力最优资源,确保小程序使用的流程。rbvesmc
在手机使用过程中,偶尔出现的卡顿,就可能是由调度机制的不完善造成的;也是过去我们常说Android系统“卡顿”玄学的部分由来。rbvesmc
所以联发科提出了一个相对极端的场景:后台放个可100%占用CPU的程序,此时前台再跑大型3D游戏。则在天玑调度引擎的辅助下,游戏跑在天玑9400之上,依然可满帧运行;而天玑9300和骁龙8 Gen 3就可能连一半的帧率都跑不到了。这就是调度的威力。rbvesmc
 rbvesmc
rbvesmc
除了上述重载场景,在轻载场景下,联发科终于也开始正视用户点击app的启动响应时间,及“启动响应误差”了。App启动响应大约可以定义为,点击操作到第一帧画面弹出放大,这之间的响应时间;而响应误差,则是指每次进行相同操作的响应时间差异。rbvesmc
再加上滑动启停的跟手程度,联发科表示,近些年他们对UX做深入研究,发现用户对操作“卡顿”与否或体验是否流畅,与这些要素有相当大的关联,而iPhone是其中做得相当不错的。rbvesmc
天玑9300已经就这几项参数做努力,天玑9400则期望做到app启动响应曲线的更扁平,以及滑动启停的更迅速。rbvesmc
前者目前据说已经<200ms,向着100ms推进,且确保每次操作的误差可控(联发科的数据是,比骁龙快2倍以上);后者则在实验室达成了启110ms、停40ms延迟响应的理想结果,只不过还需要与合作伙伴做更进一步的协同和落地。rbvesmc
 rbvesmc
rbvesmc
这在我们看来是Android生态未来发展及体验提升的重要一步,现如今也终于看到联发科带头推进了。而且很难得的,有芯片企业愿意将精力真正投入到使用体验,而不单是市场看重的跑分上。rbvesmc
补充一点:上述“轻载场景”更相关用户体验,与天玑调度引擎的关联在于,毫秒级响应也需要调度引擎确保操作过程不会被打断,包括CPU满载情况下的app启动速度,以及帮助达成诸如app启动响应误差尽可能小这类目标。rbvesmc
Part 4:智能体化AI,天玑AI生态野心
去年天玑9300发布会的报道文章里,我们就提到以往手机芯片发布会重头戏的CPU和GPU,现在开始给NPU/APU让道了。天玑9400发布会也不例外,联发科将最多的时间分配给了AI技术,这次是智能体化AI。rbvesmc
天玑9400的AI处理单元更新至NPU 890。除了ETHZ AI Benchmark v6.0跑分超过6700分,较上代提升1.4倍;达成上代同性能的功耗则下降了35%这样的量化数字之外;更重要的还是在于NPU本身的改进,及天玑AI生态的进化。rbvesmc
 rbvesmc
rbvesmc
先抛开联发科在PPT上给NPU 890加的这么多特性描述不谈——理解了联发科的思路,这张PPT的内容自然也就理解了。基于文首肯德基点单的例子,我们可以将“智能体化AI”总结为,让手机成为更主动的AI管家,会基于周围环境、记忆的个性化需求,去主动思考、计划与执行。rbvesmc
为达成这一目标,联发科认为在智能体化AI上,至少需要4项关键技术投入。(1)多模态用户输入支持,MoE(专家混合模型)支持;(2)视频生成,典型如将静态图片转为动态画面:(3)天玑AI智能体化引擎;(4)端侧LoRA训练。以下一个个来看。rbvesmc
首先,多模态输入至少就需要涵盖文、声、图。比如拍张照给AI助手看的同时,还对她说出需求。手机这类端侧设备达成多模态输入的最大挑战,在于输入数据量会因此变大,“至少需要8K以上的输入文本”,也就会对内存容量产生不切实际的需求。rbvesmc
联发科的解决方案是“低位宽KV缓存”(low-bit quantization for KV cache, 一种针对LLM压缩KV cache尺寸的方案)技术,结合GQA(grouped-query attention,一种将query heads做分组,共享KV矩阵的优化方案)据说能降低50%的内存用量。rbvesmc
最终结果是输入文本长度提升至32k,相比上代提升8倍——整体也就为多模态输入提供了基础。另外多模态输出能力也达到了50 tokens/s的水平。rbvesmc
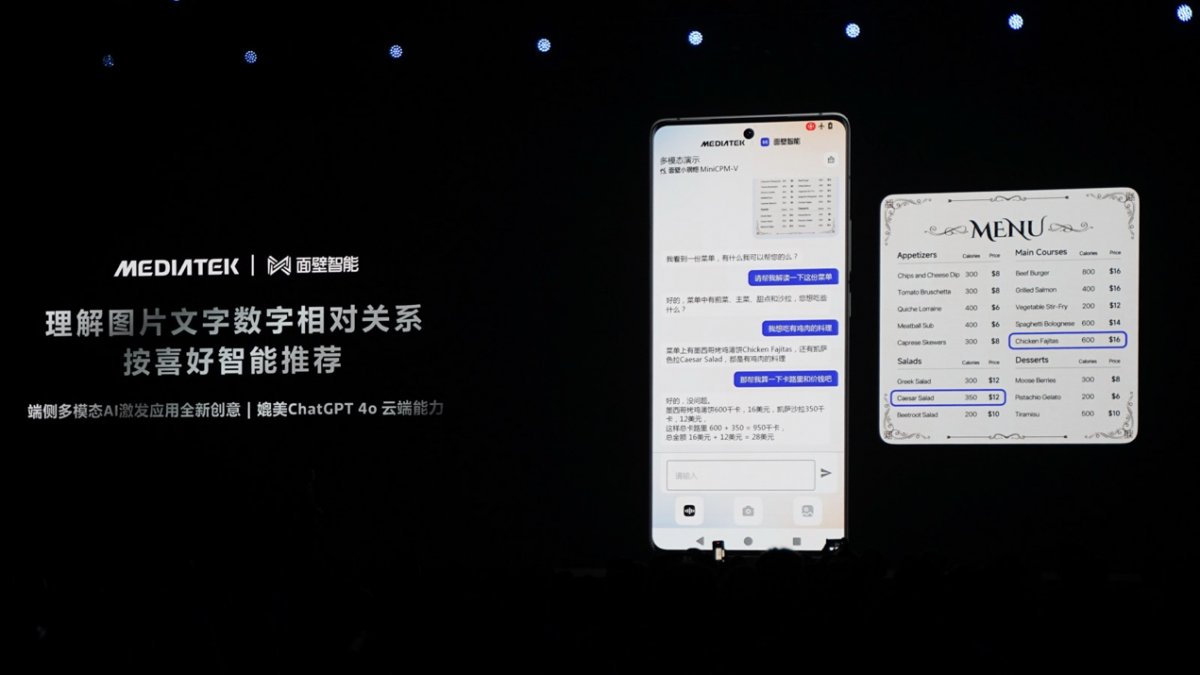 rbvesmc
rbvesmc
现场联发科演示了借助这样的能力,在看不懂英文菜单时,只需要用手机拍摄菜单,直接和AI助手对话,让她基于你的个性化需求来推荐菜品,乃至计算卡路里、价格等…这也是与面壁智能的合作成果,显然离“智能体化AI”、主动式AI助手更进了一步。rbvesmc
至于MoE模型支持,在手机上应该也是第一次。对此,天玑9400“所有运算都在硬件层面做了优化和加速”,“完整相容NPU”。rbvesmc
其次,是本次宣传的重头戏之一,端侧视频生成——也就是将描述文字或静态图片转为会动的视频。理论上以手机端侧算力,要实现这样的生成式AI能力还是很勉强的。rbvesmc
此时一般思路是做硬件加速。所以NPU 890新增的时域张量硬件指令加速,和本次发布的高画质DiT(Diffusion Transformer)就派上用场了,而且是基于静态图片+运动轨迹的“高画质视频”。虽说时域张量硬件加速的用途应当不只是生成视频,但总感觉联发科为此堆了DSA还挺奢侈的。rbvesmc
原有文生图能力自然也获得了大幅提升,生图速度至多快100%;且这次更强调Stable Diffusion XL高清文生图。联发科的数据是,相较于此前不得不借助云上算力来生图,考虑网络延迟及请求排队问题,天玑9400的端侧SDXL生图速度还比云生图快了2倍。rbvesmc
 rbvesmc
rbvesmc
第三,天玑AI智能体化引擎(Agentic AI Engine)。我们理解这里的“引擎”本质上是联发科想要构建智能体化AI生态的载体。它不是某个具体的硬件或软件组件;也真正体现了联发科构建生成式AI生态的野心。rbvesmc
比如在该生态下,AI模型与app分离——app如果需要使用AI模型,可访问集中化的端侧模型服务;其次在于结合RAG与LoRA,实现有上下文场景、个性化的AI体验;还有提供标准化的定义接口,app使用标准接口就能与其他app做沟通与交流——实现跨应用的串接与整合。rbvesmc
相关“天玑AI智能体化引擎”,联发科在媒体会上谈的篇幅并不多。我们认为,这个概念一方面是从更底层、全局地铺陈AI服务,对Android平台原本碎片化的AI实现是个好事;但与此同时,这种生态构建的难度也不小。rbvesmc
因为联发科在此面临的竞争对手不仅是同生态位的高通,还在于Android生态链条上,其他各层级参与者。不出意料的,联发科也特别针对天玑AI智能体化引擎,发起了“先锋计划”。会上公布的参与者包括荣耀、OPPO、vivo、小米、传音等。rbvesmc
 rbvesmc
rbvesmc
具体到app,文首所说的肯德基app就是借助该引擎达成了对应的智能体化AI能力。其他已经做出此类“智能体化”支持的app还有携程、全民K歌、猫眼、高德地图、酷乐潮玩等。而在AI模型端,接入天玑AI生态的参与者们——包括百度、百川、Meta等,应当都能为此贡献力量。rbvesmc
所以这是个涉及AI模型企业、app开发者、操作系统供应商、手机OEM厂商等多重角色的生态。后续的天玑开发者大会大概会有相关天玑AI智能化引擎的更多信息披露——这无疑是个重头戏。rbvesmc
最后一项关键技术,就是端侧LoRA训练。以往的天玑新品发布会及开发者大会,联发科也总在提LoRA技术的重要性。不过去年LoRA训练还是在云上进行的,但在AI愈发注重隐私、个性化和实时性需求的当下,联发科认为能在本地做LoRA训练是必要的思路。rbvesmc
 rbvesmc
rbvesmc
LoRA本质上作为一种高效的fine-tuning技术,也的确是本地实现AI模型个性化适配的绝佳方式。rbvesmc
NPU 890的新特性注解中有一项“Backpropagation算子硬件训练加速”主要就是为此准备的。Backpropogation本身就能提升LoRA本地训练的效率。而硬件加速,应该是将所谓“反向传播”的某些原本要跑在CPU, GPU上的逆运算也都搬到NPU上以提升速度和效率。rbvesmc
从前述时域张量指令加速和此处Backpropagation算子硬件训练加速不难发现,联发科发展AI的决心,以及特定的判断,还真是堪称快准狠——而且要考虑手机AP SoC长达12-18个月的设计周期,考验的还真是芯片设计企业的远见和一点点的运气。毕竟行业里还没有其他人这么做。rbvesmc
有关端侧LoRA训练,发布会上令人印象比深刻的应用案例,是联发科与虹软已经落地的合作:比如手机拍到某个朋友的照片是糊的,则借助端侧LoRA训练特性,让AI模型学习相册中该好友其他清晰的照片,最终应用到这张模糊的照片上,实现人像的清晰化。其效果会远好于超分、去模糊之类的常规算法。rbvesmc
 rbvesmc
rbvesmc
整个过程完全在本地进行,也就没有了隐私和安全方面的顾虑。rbvesmc
理解了上面这4项关键技术,对于NPU 890的诸多特性自然也就有了相对更深入的理解。而NPU 890显然也更是“应用导向的芯片设计”这一思路的鲜活力证。rbvesmc
Part 5:U艺术“后满帧时代”的GP
说完CPU和NPU,最后要谈的自然就是天玑9400的图形性能与新特性了。这部分我们分3大点来谈:(1)游戏性能提升与功耗降低,GPU的配套改进;(2)天玑9400引入的OMM特性;(3)其他图形新特性,及AI的加持。rbvesmc
先谈谈图形与游戏性能、功耗方面的变化——这也是普通用户最关心的。相比天玑9300,其GFXBench Aztech Ruins Vulkan跑分提升38%,Manhattan 3.1提升18%,还有更体现当代游戏负载的3DMark Steel Nomad Light提升了多达41%;rbvesmc
 rbvesmc
rbvesmc
以及《绝区零》《原神》《星穹铁道》这三款手机最难征服的游戏,天玑9400也能30分钟“满帧”(60fps)跑。rbvesmc
所以联发科说这是个“后满帧时代”,一方面为游戏开发者提供了更高的图形性能上限和更多的手游可能性;另一方面至少现阶段,从原本追求性能满帧,到现如今满帧前提下尽可能低的功耗,达成更低的发热和更久的游戏续航。rbvesmc
所以在满帧的情况下,天玑9400跑《原神》功耗低19%,跑《星穹铁道》功耗低了32%,跑《绝区零》功耗也低了29%。从极客湾刚刚公布的实测结果来看,天玑9400的GPU能效已经全面超越苹果A18 Pro。rbvesmc
 rbvesmc
rbvesmc
天玑9400所用的也是基于Arm最新的第5代GPU,Immortalis-G925,具体用了12个核心。Arm年中发布这一IP时,给出的数据是14核的Immortalis-G925相较12核的Immortalis-G720,性能提升37%。基于此可判断其每核性能提升幅度可能在17%左右。rbvesmc
这其实与天玑9400在图形性能测试中的得分提升幅度,是不大相合的。只不过即便是图形性能专项测试,测的实际也是系统性能。包括天玑9400的CPU、存储子系统、芯片系统设计可能都会产生正面影响。且考虑Immortalis-G925还达成了更低的功耗,这部分功耗余量也可用于进一步提升性能。rbvesmc
值得一提的是,Arm的第5代GPU架构整体更新了HSR隐面消除技术,不再依赖于Z深度排序来决策画面中对象的可见性,改用一种名为Fragment Pre-pass的方案——据说不需要进行基于深度做三角形排序sorting,也大大降低了CPU在这一流程中的参与度,大幅提升了效率。rbvesmc
 rbvesmc
rbvesmc
这对图形渲染管线来说绝对是个大幅更新。基于现有程序代码差异,这一改进可能本身也会影响不同图形测试的结果。rbvesmc
另外,这代GPU也有光线追踪方面的性能显著改进。联发科提供的数据是在3DMark的光追Solar Bay测试中,天玑9400性能较9300提升40%。在相关光追的图形特性上,天玑9400的亮点之一在于新增了OMM(Opacity Micro Map)微映射透明度技术。rbvesmc
Ada Lovelace发布时,我们大致解释过OMM技术。以绘制一片树叶为例,绘制像下图中这样一片树叶,一般是搞个矩形并在其上应用纹理。当然叶子本身不会是矩形,则需要某部分为透明状态。对于光线追踪流程而言,要搞清楚某个位置是否透明,需要shader参与检查并反馈给光追单元。rbvesmc
英伟达为GeForce 40系GPU的光追核心专门引入了OMM引擎负责有关透明度状态问题,降低了shader的负载。简单来说,这也是个提升光追效率、节约资源的技术方案。rbvesmc
 rbvesmc
rbvesmc
联发科将OMM技术视作移动端与PC游戏的交集之一。从示意图来看, “移动端天玑OMM追光引擎”在原理上应当是相似的。不过联发科并未解释其具体实现。据说联发科已经在OMM软件算法方面投入了超过2年时间;rbvesmc
OMM特性的生态构建,包括与游戏开发者合作——《暗区突围》已经加入了这一特性,在帧率提升50%的同时,降低了10%的功耗;还有与3DMark, BaseMark等评测机构联合定义OMM评测标准…3DMark当前也已经有了专项的OMM特性测试。rbvesmc
 rbvesmc
rbvesmc
其他相关游戏与图形的技术特性,基本都是围绕联发科的星速引擎展开的。星速引擎也是过去两年配套天玑芯片,达成游戏体验优化的关键技术,涉及调度、网络、触控延迟、低功耗等技术组合方案…rbvesmc
游戏低功耗技术实现上,天玑倍帧技术2.0、星速引擎超分技术是颇具发展潜力的特性。前者是一种结合了电视插帧方案的技术;后者则有些类似于FSR超分——联发科与Arm就这项技术合作,目前正在导入手机游戏,后续《极品飞车:集结》《七日世界》预备上线该特性…这两者都是在尽可能不影响体验、减少GPU渲染负载的情况下,进一步降低功耗的技术方案。rbvesmc
最后值得一提的技术布局,是游戏与AI的结合。具体案例典型如《王者荣耀》配套的AI教练,《破碎之地》的AI队友…而且普遍是结合了生成式AI技术,可以自然语言沟通对话的。针对具体到游戏的AI开发,大约也是为了扩展天玑AI生态,联发科此次选择与Cocos引擎合作,打造端侧AI游戏开发平台,预备孵化更多能够充分利用端侧AI技术的游戏。rbvesmc
至于游戏相关的AI调度算法、网络调控、触控响应优化等,受限于篇幅,本文不再赘述。rbvesmc
Part 6:旗舰之后,引导技术发展
vivo X200系列、OPPO Find X8系列新机预计都将携天玑9400发布。rbvesmc
单纯以天玑9400在CPU、GPU和NPU三方面的性能与能效优势,以及这些数据可能给竞争对手带来的压力做结尾,感觉还是不够。处理器性能与能效领先,应当只是这些年联发科影响力提升的一种表现。rbvesmc
自天玑9000系列在旗舰定位的手机产品上站稳脚跟,到这一代天玑9400的发布,联发科的气质型已远不似往昔。从本次发布会活动的几个具体事件可体现这种变化。rbvesmc
 rbvesmc
rbvesmc
其一,光是天玑9400发布会之前的媒体技术沟通会就长达三个多小时,而且各分支技术的讲解也只做到了一笔带过,可见当下其技术储备之丰富非几年前可比;rbvesmc
其二,联发科这次还很少见地将天玑调度引擎这样的软件,作为技术重头戏做介绍,既体现芯片行业的时代趋势变迁,也能表现联发科在手机领域的着力点和影响力正在拓宽;rbvesmc
其三,天玑芯片发布会更频繁地出现“生态”一词,以及天玑开发者大会的开启、与上下游合作伙伴的合作,还有具体到本次天玑智能体AI引擎的布局,都能体现联发科构建庞大生态帝国的野心;rbvesmc
最后,包括OMM追光引擎,星速引擎,对app启动响应延迟及误差、滑动启停体验的研究等技术项目,都能看出天玑成为旗舰手机芯片以后,正从单纯的旗舰追赶者进化为技术引领者——这一步是相当不易的。rbvesmc
而真正能够体现这一点的,在于NPU 890的诸多硬件加速创新。在我们看来ETHZ AI Benchmark跑分并不是关键;而为实践智能体化AI概念,在其中固化特定算子以达成特定功能的硬件加速或许是种趋势写照,但更重要的是对技术的引导和引领。这在几年前的联发科身上是看不到的。rbvesmc

- 上一篇:最高奖补百万!深圳启动鸿蒙人才培养计划
- 下一篇:返回列表
-
微信扫一扫,一键转发
-

关注“国际电子商情” 微信公众号
- 最高奖补百万!深圳启动鸿蒙人才培养计划
每年培训超3000人。
- 国内首家功率器件上市企业股东被立案
国际电子商情讯,上周五(10月25日),吉林华微电子股份(以下简称华微电子)发布晚间公告称,公司控股股东上海鹏盛科技实业有限公司(以下简称上海鹏盛)于10月25日收到证监会的立案告知书。
- 英特尔宣布扩容成都封测基地
国际电子商情讯,今日(10月28日)英特尔在其微信公众号发文宣布,“扩容程度封装测试基地,加强本土供应链和客户支持”。
- 2024国际RFSOI论坛在沪举办:新热点带来新机遇
2024年10月24日,上海迎来了一场备受瞩目的行业盛会——2024国际RFSOI论坛。这场由新傲科技、新傲芯翼、沪硅产业及芯原股份联合主办的论坛,在上海浦东香格里拉大酒店盛大开幕。
- 芯片“出海”潮再起,卷向海外一定是生路?
新一轮芯片“出海”潮的目的地,不但包括距离较近的东南亚、印度,还有更远的南美、欧洲等地区,反映了中国芯片企业的多元化布局和战略调整。
- Wolfspeed搁置德国SiC工厂兴建计划
国际电子商情24日讯 继英特尔宣布推迟在德国投建晶圆厂之后,美国芯片制造商Wolfspeed也搁置了在德国恩斯多夫建立半导体工厂的计划……
- 特斯拉2024年Q3净利润超预期,马斯克称仍面临利润压力
国际电子商情讯,北京时间10月24日,特斯拉对外公布了2024年Q3财报,该季营收为251.82亿美元,净利润为21.67亿美元,尽管该营收略低于市场预期,但其盈利却超出了预期。
- 2024年全球硅晶圆出货下降2.4%,明年将强劲反弹
国际电子商情23日讯 市调机构在最新报告称,2024年全球硅晶圆出货量约为121.74亿平方英寸(MSI),较去年同期下滑约2%。但随着晶圆需求继续从下行周期中复苏,2025年出货可望迎来约10%的强劲增长……
- 外交部证实!大众汽车中国高管因吸毒被遣返
国际电子商情讯,在今日的外交部例行记者会上,外交部发言人针对“大众汽车一高管被遣送出境的报道”做出回应……
- FD-SOI卷工艺:三星/ST力推18nm,GlobalFoundries直奔12nm
第九届上海FD-SOI论坛今日在浦东香格里拉酒店召开,作为一年一度的FD-SOI全球顶级盛会,行业上下游也是悉数出席,作为该领域的几大玩家,三星、ST和GlobalFoundries分别分享了最新的进展。
- 高通推出两款车载平台,人工智能性能大提升
国际电子商情讯,北京时间10月23日凌晨,高通公司在“2024骁龙峰会”上宣布,推出两款新型车载平台——Snapdragon Cockpit Elite(骁龙座舱至尊版)和Snapdragon Ride Elite(Snapdragon Ride至尊版)。这两款平台采用OryonCPU,旨在为下一代汽车带来更好的性能和智能表现
- Infinera将获美国芯片法案9300万美元资助
国际电子商情22日讯 近日,美国商务部已经与美国光纤网络供应商Infinera签署了一份非约束性的初步备忘录,后者预计将获得高达9300万美元的直接资助。
- 2024全球电梯制造商10强榜单,奥的斯、迅达、通力位居前三
2024全球电梯制造商10强榜单10月25日在北京发布。
- 总规模30亿,又一集成电路产业基金落地
近日,总规模30亿元的集成电路产业基金落地青岛自贸片区。
- 国际首款,中国这一芯片成功量产!
近日,由中核集团原子能院核安全与环境工程技术研究所研发的国际首款X/γ核辐射剂量探测芯片成功实现量产,实现
- 2024全球最大100家军工企业排行榜,6家中企上榜
美国《防务新闻》(DefenseNews)发布《2024全球最大100家军工公司》(Top100DefenseCompanies2024)排行榜,洛克
- 国内企业级SSD厂商究竟在拼什么?
随着AI应用快速普及,市场对高性能、高可靠性的存储产品需求与日俱增,企业级SSD正受到前所未有的关注。全球SSD
- vivo蝉联榜首,中国智能手机市场第三季度延续反弹,增长4%
2024年第三季度,中国大陆智能手机市场在暑期及开学购机旺季的推动下延续了反弹的步伐,出货量同比增长4%至6910
- 全球光刻机市场竞争加剧,ASML财报引发关注...
近日,ASML发布最新三季度财报后,股价创26年来最大跌幅引起市场极大关注。
- 聚焦集成电路与人工智能等研发,工信部划重点
10月23日,国务院新闻办公室举行新闻发布会发布重要讲话,其中针对集成电路、人工智能等行业的发展发表最新指引
- 预计2025年成熟制程产能将年增6%,国内代工厂贡献最大
根据TrendForce集邦咨询最新调查,受国产化浪潮影响,2025年国内晶圆代工厂将成为成熟制程增量主力,预估2025年全
- 2024年,印度个人智能音频设备市场展望
2024年,印度的音频市场将继续波澜涌动,仅第二季度的出货量就达到1900万台,同比增长19%。TWS已在该细分市场中确
- 逾21亿元,SK集团收购越南半导体公司ISCVina
据越南北部永福省政府网站上的一份声明,韩国企业SK集团收购了越南永福省的半导体公司ISCVina,交易金额为3亿美
- 无需半导体材料的电子器件问世
美国麻省理工学院团队在电子制造领域取得一项重要进展:他们利用全3D打印技术,制作出了不需要半导体材料的有源
- 集成系统创新,连接智能未来 -- 2024芯和半导体用户大会隆重召开
集成系统创新,连接智能未来 -- 2024芯和半导体用户大会隆重召开
- 西部数据亮相2024安博会,展示智慧视频、数据中心创新存储产品
在2024年10月22-25日举办的2024年中国国际社会公共安全产品博览会(以下简称“安博会”)上,西部数据携旗下产品
- 通过基于AI的异常检测实现工业过程转型
86%的制造业高管认识到智能工厂将在未来五年内提升竞争优势,AI 将在制造业中发挥重要作用。
- 德州仪器全新可编程逻辑产品系列助力工程师在数分钟内完成从概念
德州仪器的全新 PLD 产品系列能够在单个器件中集成多达 40 个组合和顺序逻辑及模拟功能,与分立式逻辑实
- ASM推出全新PE2O8碳化硅外延机台
全新推出的PE2O8碳化硅外延机台是对行业领先的ASM单晶片碳化硅外延机台产品组合(包含适用于6英寸晶圆的PE1O6
- 摩尔斯微电子推出社区论坛与开源GitHub资源库
新资源的上线将加速全球工程师与开发者的Wi-Fi开发进程。
- Vicor发布最高密度车规级电源模块,支持电动汽车实现48V电源系统
2024年10月16日,Vicor发布了三款用于48V电动汽车电源系统的车规级电源模块。这些模块提供业界领先的功率密度
- 创实技术亮相2024慕尼黑华南电子展,掘金半导体产业新一轮增长周期
本届慕尼黑华南电子展3号馆3A09展台上,创实技术和创华芯再次联合展示。创实技术重点展示了日本顶尖电源管理I
- 汇顶科技智能音频放大器TFA9865荣获两项行业大奖
汇顶科技智能音频放大器TFA9865凭借出色表现,荣获“IoT年度产品奖”与“2024年度硬核IP产品奖”两项殊荣。
- Littelfuse推出行业首创超大电流SMD保险丝系列
以紧凑的SMD封装提供150A和200A额定电流,简化设计并节省PCB空间。
- 电化学传感技术的革新之作:Sensirion推出新一代甲醛传感器SFA40
全球前沿的环境传感解决方案提供商盛思锐(Sensirion)宣布,其甲醛传感器产品组合又添新成员SFA40。SFA40代表了
- 凯新达科技--获得质量、环境、职业健康安全“三体系”认证,助推公